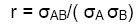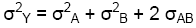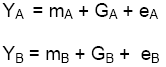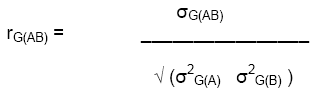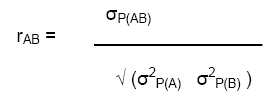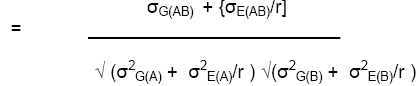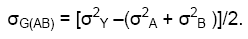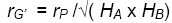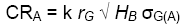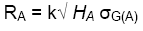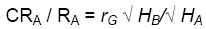|
|
|
|
|
|
|
|
Breeding theory |
|
|
|
|
Correlations among traits: implications for screening |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Introduction
Many important traits are positively or negatively correlated, because they are controlled by some of the same genes or because they are developmentally or structurally related. An example of a genetic correlation due to a common set of genes might be the association between grain zinc and iron content; varieties that accumulate high concentrations of one element usually also accumulate the other, probably because of a common uptake mechanism. An example of a structural association between traits is the relationship between biomass yield and grain yield; these traits are highly correlated simply because grain yield is a large component of biomass yield. Correlations between genotypic effects for different traits are called genetic correlations (rG) .
Breeders are concerned with genetic correlations because:
In this lesson, we will learn how to estimate genetic correlations, and how these estimates are used to predicting selection response. |
|
|
|
|
1. Variances, covariances, and correlations
The product-moment correlation: For 2 variables, A and B, the product-moment correlation is:
The variance of a sum: If Y = A + B, then
|
|
|
|
|
2. Genetic covariances and correlations for traits measured on the same plot
If 2 different traits (say, height and yield) are measured on the same plot, both genotypic and environmental effects can contribute to the correlation between line means:
The genetic correlation is the correlation of the genotypic effects for the two traits:
There is also an environmental correlation between plot residuals for different traits.
The phenotypic correlation is the correlation of the line or genotype means for the two traits:
Note that, as the number of replicates increases, rP approaches rG. So phenotypic correlations are fairly good estimators of genetic correlations in well-replicated trials. |
|
|
|
|
3. Estimating rG for traits measured on the same plot
There is an easy way to estimate rG with any software that performs ANOVA.
To estimate rG, we need to estimate σG(AB) , σ2G(A), and σ2G(B).
We have discussed estimation of σ2G(A) and σ2G(B) at length in the previous lesson.
To estimate σG(AB) , we perform the following steps:
Click on the icon for an example/exercise:
|
|
|
|
|
4. Genetic correlations for the same trait measured in different environments
Often, it is of interest to measure the genetic correlation for yield or another trait in measured in different environments. If this genetic correlation is high, the environments can be treated as part of 1 TPE, and it may be assumed that there is little GEI between them.
Assume that the two trials or environments are called A and B. The model for each site is:
If the entries are re-randomized for each site, the G’s are correlated, but the e’s are not. Any covariance across sites is the genetic covariance. Genetic variances within sites are estimated by the methods used in the previous lesson.
The genetic correlation is then estimated. As the number of reps within each site or group of environments increases, the line mean correlation (or phenotypic correlation) approaches 1.0
Note that the correlation between any 2 environments can not exceed the repeatability (H) within the environments.
|
|
|
|
|
There is an easy way to estimate the genetic correlation across environments, which we will call rG’ to distinguish it from the genetic correlation within environments.
To estimate it, we need to know:
Example: Consider a TPE that we might wish to divide into 2 subregions, A and B. A set of 50 varieties is tested at 3 sites within each subregion. Means are estimated for the varieties over trials within subregions.
The phenotypic correlation for means across subregions is calculated as 0.55. Line mean H for means estimated over 3 trials is 0.7 for subregion A and 0.6 for subregion B.
Note that even though the phenotypic correlation across environments was quite low, the genotypic correlation was high. Phenotypic correlations are low because of the obscurring influence of random environmental “noise”.
|
|
|
|
|
6. Predicting correlated response in a target trait resulting from selection for a secondary trait
The main reason for estimating a genetic correlation is to determine if we would have a greater response if we select for a secondary trait than for our target trait. Selecting for a secondary trait when our goal is to improve some other target trait is referred to as indirect selection. Indirect selection produces a correlated response in the target trait, if the target trait and the secondary trait are correlated. Correlated response in trait A to selection for trait B is predicted as:
Remember from Unit 7 the equation for direct response:
If k is the same for both trait A and trait B, we can determine from these 2 equations if direct or indirect selection is likely to be superior:
In other words, indirect selection for a secondary trait will be superior if the heritability of that trait is high, and the correlation between the traits is close to 1.
Occasionally, breeders and physiologists wishing to select for improved performance under a particular environmental stress find it difficult to select directly for yield under that stress.
An example of this situation is screening for drought tolerance. It can be difficult to evaluate breeding lines for drought tolerance, because drought occurs irregularly. Many researchers have tried to use secondary anatomical or physiological parameters like root-pulling resistance or root mass to assist in identifying drought-tolerant genotypes.
A drought-tolerant genotype is one that produces a high grain yield under a particular type of drought tolerance. Therefore, for a secondary trait to be useful in screening, it must have a high genetic correlation (high rG) with yield under stress and must be repeatably measurable (high H).
For practical use in a breeding program, the secondary trait must also be inexpensive and easy to measure in large trials or nurseries.
The relationship between some secondary traits and drought tolerance in rainfed lowland rice: Click on the icon to see an example from Raipur, India
|
|
Let's conclude |
|
Summary
|
|
Next lesson
|
|
This ends module 2. The next module is about managing a breeding program. |
|
|
|
|
|
|



.gif)